|
In today's dynamic business landscape, the importance of effective Learning and Development (L&D) cannot be overstated. However, many L&D departments find themselves under significant pressure, often facing budget cuts as their contributions are scrutinized. This ongoing struggle is not simply administrative; it stems from deeper issues surrounding alignment, measurement, and the recognition of skills gaps within organizations.  Dynamic dashboard displaying total conversations analyzed, the skills exhibited by individuals within each conversation, and their grouping by performance using Machine Learning and Generative AI. If you had to pick two people to work together in a shift at the reception of a hotel, how do you think you could use this data and the insights? (hint: take a look at the performance clusters) The Challenge with Traditional Learning & Development First and foremost, a common roadblock for many L&D departments is their hesitation to measure and compare the impact of their initiatives. This reluctance often arises from a fear of negative outcomes or simply not knowing how to align learning with tangible business results. Without distinct metrics, demonstrating the value of training programs becomes a daunting task, particularly when addressing C-suite executives who are primarily focused on immediate business outcomes. Additionally, there exists a significant disconnect between executive priorities and the reality of skills gaps within the workforce. Leaders may either fail to acknowledge these gaps or lack consensus on the specific skills needed for organizational success. This misalignment complicates the mission of L&D departments, leaving them to navigate their objectives without adequate resources or support. Moreover, this sentiment is prevalent among employees (and rightly so): There’s not enough time to do my job, how do you expect me to find time to do ‘learning’ ? This can significantly hinder the success of L&D initiatives. Employees often feel overwhelmed with daily responsibilities, which makes the idea of dedicating time to learning seem impractical, if not impossible.
The Solution: Embracing Cohort-Level Measurement A compelling solution to these challenges lies in providing employees with the opportunity to develop skills relevant to their job, and then, measuring these skills at a cohort level. By shifting the focus from individual assessments to the collective capabilities of teams or departments, L&D can gain valuable insights into the overall skills landscape. This approach not only illuminates group strengths and weaknesses but also connects these skills to real-world performance metrics, allowing organizations to bridge the gap between training initiatives and business outcomes effectively. Identifying skills gaps on a cohort level enables organizations to understand how deficiencies in specific areas directly impact productivity. For example, if a team struggles with a critical collaborative skill (such as transparency and grace during communication), it can lead to delays in project delivery, diminished customer satisfaction, or worse, costly attrition or turnover in the workforce. When L&D departments can effectively illustrate these connections, they acquire a powerful tool for advocating their initiatives, gaining the support and budget necessary from leadership. Personalized Learning and Upskilling True personalized learning is about tailoring educational experiences to align with the unique needs of individuals within a cohort. Each employee brings different strengths and areas for development. By leveraging real world data to customize learning paths, organizations can significantly enhance engagement, retention, and application of knowledge. Upskilling, which refers to broadening the capabilities of existing employees, emerges as a crucial strategy in this context. In an era where job roles continuously evolve, organizations must prioritize upskilling to stay competitive. This proactive approach not only fosters employee satisfaction and retention but also ensures that the organization is well-equipped for future challenges. The Generative AI Advantage As organizations explore methods for implementing innovative learning strategies, incorporating Generative AI tools offers a significant opportunity. Generative AI facilitates scalable training initiatives, enabling personalized experiences that adjust in real time based on real-world business data, learner feedback, learner needs, and their performance. Additionally, AI streamlines the measurement of training efficacy, providing ongoing insights into both individual and cohort-level performance. Contextually relevant training can be delivered, ensuring that learning experiences are applicable and engaging. The experiential nature of AI-driven training means employees are more likely to retain information and apply it effectively in their roles. To see an example of one such highly effective application in the Hospitality Industry, head over to Rapport, and try the Training Simulation demo. Conclusion: Rethinking L&D for Organizational Success In conclusion, measuring skills at the cohort level is not merely an operational recommendation; it is a strategic necessity. As organizations navigate the complexities of a constantly evolving landscape, aligning L&D initiatives with business outcomes through solid measurement will unlock new pathways to productivity and growth. By embracing innovative tools like Generative AI, businesses can cultivate a learning culture that thrives on adaptability and continuous improvement, ultimately leading to long-term success. If you’re passionate about the future of work, and want to embrace opportunities to transform not only how we learn, but also how we achieve excellence together in the workplace, reach out to us via email to experience a demo of our platform. With Relativ’s custom AI models, and in partnership with Rapport, we can create highly relevant and timely experiential learning, scalable across your workforce, to give you a business advantage in a manner that wasn’t possible before. With data and insights from our proprietary conversational AI, we can now provide executive leadership teams with tangible measures of the success of any training programs. Sales, hospitality, leadership development, and customer success teams represent just a few of the early adopters working with us. Join them in helping us redefine the future of work!
0 Comments
For a year, I've been sporadically writing blog posts exploring why Generative AI is poised to drive academic and business outcomes. In my previous posts, I focused on building trust, safety and transparency in Generative AI applications, and before that, wrote about career readiness preparation, and how organizations can leverage the unique properties of Large Language Models (LLMs) to provide personalized feedback for their end users, at scale, on a 24/7, 365, on-demand basis. In this blog, I will continue to build on that chain of thought (pun intended) and explore the world of continuous learning and development (L&D) in corporate settings. There are parts of this blog that may require a deeper dive into some technical bits, references to which I have provided in the blog. For those of you that want to skip past these bits, but still want to tap into the power of Generative AI for L&D, please feel free to reach out to me directly and I will do my best to guide you or help. Optimizing your workforce: An important topic of discussion. In today’s fast-paced corporate landscape, the ability to harness data effectively can make a world of difference in driving business outcomes. Among the tools available, conversational analytics, powered by Generative AI Models, emerges as a game-changer, providing insights that are often overlooked. By analyzing the nuances of employee interactions, organizations can uncover patterns, preferences, and areas for improvement, ultimately fostering a culture of continuous learning and adaptability. As companies strive to enhance engagement and productivity, leveraging the power of conversational analytics equips leaders with the knowledge necessary to tailor training initiatives and optimize workforce capabilities. This data-driven approach emphasizes an important aspect of talent development: the need to map learning and development (L&D) efforts to business outcomes, ensuring that skills acquired during training translate directly into enhanced organizational performance. The Need to Map L&D to Business Outcomes A study commissioned by Middlesex University for Work Based Learning found that 74% of workers from a sample of 4,300 felt they weren't achieving their full potential at work due to lack of development opportunities. This article from the HR Magazine highlights research and several interesting statistics that show how hungry people are for opportunities to learn on the job. And this translates directly to a burden on the organization’s Learning & Development (L&D) departments, who are often short-staffed, resource constrained, or both. I have seen and experienced too often, the misconception that learning and development is primarily associated with content creation, and serving up tutorials, lessons, regulatory sessions, or similar modules, at discrete instants in time, to check a box within an organization. This highlights a pervasive misconception that learning and development (L&D) is primarily associated with content creation and compliance tasks done only at specific intervals. Often, there is the exercise of “needing to map” the learning and development function within the organization to the organization’s objectives or goals. While there are healthy debates and multiple viewpoints on this aspect of L&D (and there is no right or wrong approach, since all organizational cultures and workforces are nuanced and unique), there is also a seismic shift with Generative AI that is poised to flip the “need for mapping” on its head. By tapping into the underlying architecture of Large Language Models, we can do things that weren’t quite possible before. For example, by having a data strategy in place, Generative AI can help automatically identify and map the learning & development functions based on business outcomes. This is where we start to get into the interesting world of Predictive AI. If this topic is still holding your attention, read on, because I will try to explain this idea further with some real examples. Applications for Sales & Manager Training Predictive analytics offers organizations the ability to forecast training needs and outcomes by analyzing patterns from historical real-world data. The staggering statistic below that I computed using some back-of-the-envelope math should give anyone doubting if we have any available data, food for second thought: The daily meeting time across Microsoft Teams and Zoom combined is roughly ~362 million hours ! [1, 2] So, what are organizations doing with all this data? More importantly, what can organizations do with this data, particularly if they were to begin using advanced Conversational Analytics? The possibilities are endless, but what matters most is making sure that the choice is well-aligned with business outcomes. As an example, in the realm of sales training, organizations can utilize predictive analytics to identify the characteristics of top performers and tailor programs that replicate their success traits. By understanding which training modules yield the best results, such as increased sales conversions or improved customer interactions, companies can refine their approaches to training and ensure maximum impact. Similarly, for manager training, predictive analytics can help assess the current competencies of managers and forecast the skills required for future challenges. By examining employee feedback, performance assessments, and other data sources, organizations can identify gaps in managerial skills and create targeted development plans. This proactive approach ensures that training is not just reactive to current needs but anticipates future demands, ultimately equipping leaders with the tools necessary to drive team performance and business success. And this brings me to the foundation for all of this to occur. It is imperative that organizations invest in a good data strategy that can support their workforce and L&D departments. The Data Strategy Until now, we didn’t have the ability to look at vast volumes of data and comb through them to extract insights that mattered to our academic or business context. This also meant that we didn’t really have a data strategy in place that would directly impact our future business outcomes. Sure, we all collected and saved data that mattered to us, but this data was unstructured at best, and more likely, unusable at worst. Large Language Models (LLMs) have changed that. We now know exactly how data can be used to improve the performance of these models. We also know how we can alter the final layers of these incredible neural networks with our own data to achieve novel results. In a nutshell, this data can be broken up into the following categories:
The Connection between L&D, Data Strategy, and Business Outcomes At this point, you’re probably thinking: "How does this help me with L&D and the need to map the function to business outcomes?" Well, from the previous section, we know that we can transform any data that we have into insights using the power of Large Language Models. So, the questions that we should be asking ourselves could be something along these lines, in the following order:
Applying Conversational Analytics for Insight Extraction The potential of conversational analytics, powered by Generative AI, in corporate settings is vast, particularly when it comes to extracting actionable insights from recorded meetings and calls. By leveraging the transformer architecture of LLMs, organizations can analyze conversations to identify trends, sentiment, and key topics that are impacting business performance.
Measuring the Impact of Durable Skills on Business Outcomes Once conversational analytics have been integrated into L&D strategies, measuring their impact, becomes essential for long-term business success. We can do this particularly well by leveraging the durable skills framework. Durable skills, alternatively referred to as "soft skills", such as communication, empathy, persuasion, negotiation, problem-solving, critical thinking, adaptability, and teamwork, play a critical role in enhancing employee performance and driving business outcomes. And they lend themselves very well for measurement in conjunction with conversational analytics.  To effectively evaluate success, I’d argue that organizations who are serious about positive change through training should consider the following aspects:
Conclusion: The Future of L&D through Conversational Analytics In conclusion, the integration of conversational analytics within Corporate Learning and Development strategies presents a profound opportunity for organizations to drive meaningful business outcomes. By harnessing the power of data derived from conversations, companies can gain insights that inform training initiatives, address key business challenges, and foster a culture of continuous improvement. As the workplace landscape continues to shift towards hybrid and remote settings, the relevance of conversational analytics will only increase. Organizations that leverage these insights will not only optimize their workforce but also remain agile in navigating the complexities of the modern business environment. The future of work lies in data-driven strategies where informed decision-making leads to impactful learning experiences, ultimately translating into enhanced performance and growth. At Relativ, we help organizations experiment with their own data and understand how LLMs work with different contextual information, so they can expand these capabilities and begin to measure various skills that individuals exhibit during their conversational exchanges. We have developed advanced AI models that accurately measure essential durable skills relevant across multiple industries. The consistent performance of these models across diverse contexts reinforces the essence of “durable skills”, highlighting their ability to seamlessly transfer and apply across various work environments. These models enable us to create simulated environments that facilitate high-stakes conversations, where individuals can practice and refine their durable skills. Through personalized feedback, we empower users to enhance their performance in these critical interactions. To learn more, and get a demo of our proprietary conversational analytics engine, head over to our website or reach out to us to learn how we can help you deploy your own AI models, infused with psychology, and linguistics, to empower your organization and end users with the durable skills they require to meet the challenges of the future of work.
The last 18 months or so have been one of the most exciting periods for growth of AI. It’s interesting that while the field of AI has been around for decades and maturing rapidly on its own, the introduction of Large Language Models and Generative AI has created a massive amount of adoption and interest across all communities. Perhaps one of the easiest explanations for this is the nature of the output from these AI models. They cater to one of our social needs – the need for communication / use of language to exchange information.
Unlike traditional AI models, these textual or conversational outputs from Generative AI models are not mathematical in nature or require any additional explanation. Instead, they can deliver information to us in a form that we easily understand every day. More importantly, we can “instruct” these models to provide us with outputs in a manner that we can comprehend easily, again, without the need for sophisticated programming languages or the mathematical basis required previously. In my introductory blog post, I outline some of the characteristics of Large Language Models and why they are well-suited to drive academic or business outcomes. I also highlighted the true nature of such models, the black box problem, and emergent behavior, all of which essentially boil down to this: While the application of LLMs can have a profound impact in helping societies, how LLMs work internally remains an important area of research. As more such Generative AI models become commonplace, researchers are making progress in trying to understand “how” these Large Language Models interpret information and whether their outputs can be trusted. In one such recent such ground-breaking development, researchers at OpenAI attempted to decompose the internal representation of GPT-4 into millions of interpretable patterns. According to the researchers: Unlike with most human creations, we don’t really understand the inner workings of neural networks. For example, engineers can directly design, assess, and fix cars based on the specifications of their components, ensuring safety and performance. However, neural networks are not designed directly; we instead design the algorithms that train them. The resulting networks are not well understood and cannot be easily decomposed into identifiable parts. This means we cannot reason about AI safety the same way we reason about something like car safety. In the next section, I will attempt to explain autoencoders, a type of artificial neural network, that can potentially provide some initial insights into the inner workings of large language models such as GPTs (Generative Pre-trained Transformers). Autoencoders were used by the researchers at OpenAI to identify activation patterns in the neurons and correlate them to identifiable concepts that were understandable by humans. Autoencoders Autoencoders can help understand the inner workings of a neural network by providing insights into how data is represented and processed within the network. In simple terms, it compresses input data into a smaller feature set and then attempts to reconstruct the original input from this compressed set of features. IBM has an excellent article on autoencoders for those who want more details. Here’s how autoencoders can be useful in understanding models like GPT-4: Dimensionality Reduction and Visualization:
Implementation & Results For those of you interested in code and practical implementation of autoencoders, I recommend starting with some basics. Use keras and tensorflow to perform these steps:

Once you understand how autoencoders work, we can look at how to apply this to better comprehend the inner workings of LLMs.
Applications of Autoencoders to understanding LLMs. As you are reading through this next section, please refer to the SAE Viewer from OpenAI to understand how activations occur for different concepts for GPT-4 or GPT-2. In the context of large language models (LLMs), autoencoders can be trained on the activations of the LLM. This helps to identify and visualize the features that the LLM uses to understand and generate language. To best understand this, it is worth looking at an example with some data that we can all relate to.
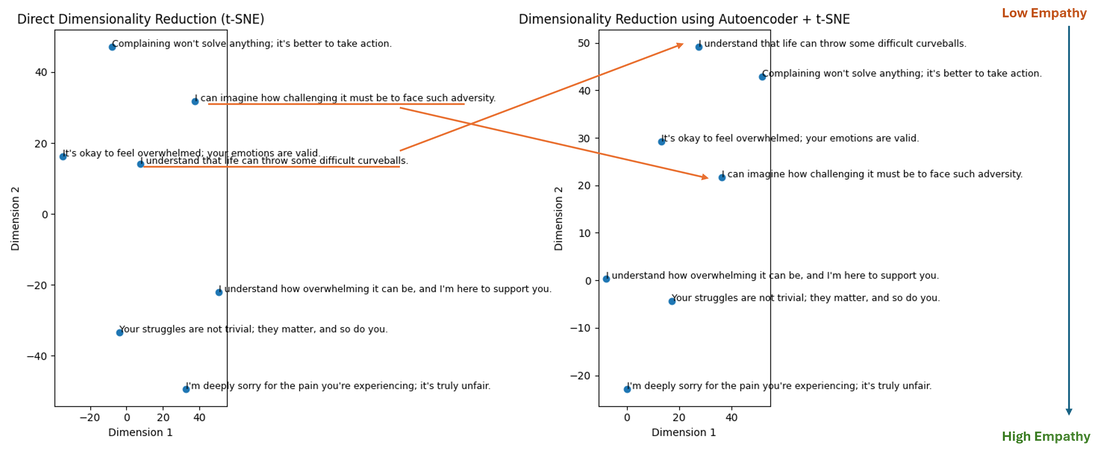
As you can see, some of the nuance in how close each sentence is in “empathy” to the other is lost in the direct embedding, but preserved with the autoencoder, allowing us to better understand how the LLM “embeds” this data and makes meaning out of it. For the image on the right, read each sentence from top to bottom, and check if you agree with the level of empathy that can be ascribed to each sentence (knowing of course that this can be subjective). Without performing a scientific analysis, I’d say that we can almost see a correlation between the embedding and the level of empathy (as indicated by the arrow on the right).
This is by no means, a comprehensive sample, and the nature of the output, its interpretation, and eventual utilization depend on various factors, including the chosen embedding model, but at least, this begins to give us some idea as to how an LLM may interpret inputs and outputs. The potential to build on this ability and its applications are what we are focused on at Relativ, my new startup, where we deploy customized AI models for personalized conversational analytics at scale. So, to recap, let’s do a quick summary of how autoencoders can be used to describe the inner workings of neural networks. Autoencoders can help by:
Implications for Transparency, Understandability, Trust & Safety One of the biggest drawbacks with the black box nature of LLMs is whether we can trust their outputs. This is particularly true if the Generative AI models are used in any capacity to provide advice, coaching, tutoring, or information that is necessary for learning and development. One such limitation of LLMs that is inherently present is termed as hallucination, which you can read more about in this article. While there are ways to mitigate this, the underlying question of why LLMs hallucinate, and how these large neural networks remain of interest. Unless we can “trust” the information provided by the AI model, which in turn translates to reliability and repeatability, and know that the information can be “safely” consumed, serious applications of AI to help us in daily life may be counterproductive. Another aspect of this is the question of “transparency” and “understandability” of AI models. This is a related aspect that governs the nature of the data used to train the neural network. The ways in which a neural network may learn information and fire activations may be largely dependent on the input data. Without transparent information on how the AI model is producing its outputs, and what data was used to train the model, it is difficult to truly “understand” what the output from the model means. This is why researchers are so keen on understanding the inner workings of neural networks. Autoencoders are one such powerful tool available to us, and researchers are already starting to make progress towards this goal. At Relativ, we continue to focus on these aspects as the cornerstones of all our customized AI models. We know what data goes in, and we define what data comes out, in collaboration with our partners and clients. If you’d like to learn more about how we can help you integrate customized AI models to support your organization’s academic or business goals, please reach out. We’re always looking for people who care deeply about the positive impact of AI on our societies while keeping privacy, transparency, trust, and safety as our most important guiding rails. I hope you enjoyed reading this as much as I enjoyed writing it! 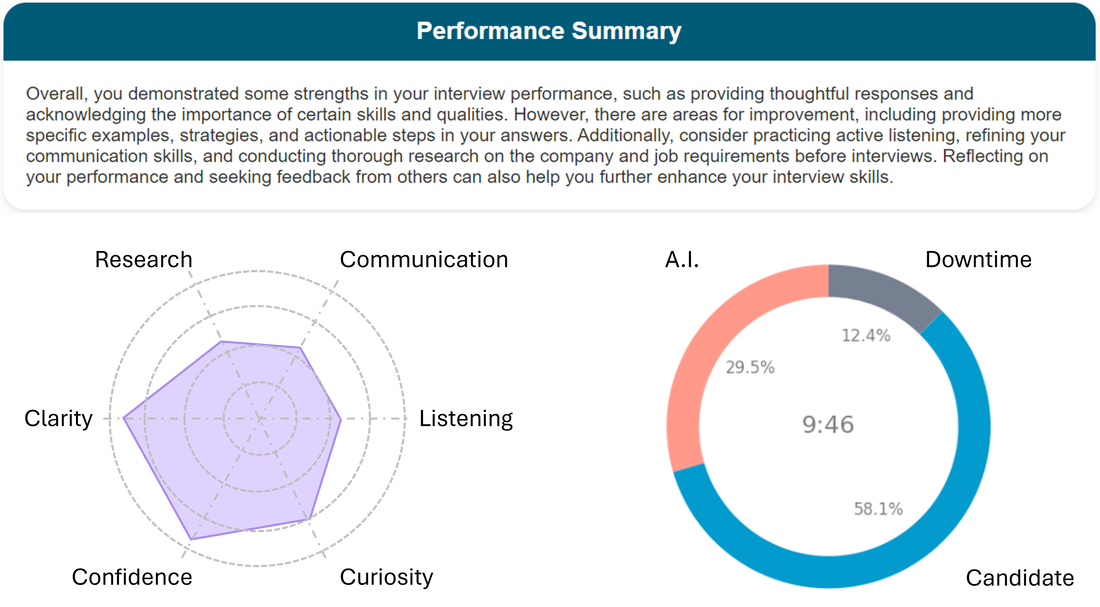 In my first blog post about Generative AI and Large Language Models (LLMs), I explained their inner workings and why they are well-suited for adoption in both academic and business contexts. I’m building on this introductory blog by diving deeper into their inner workings in specific contexts. In this second blog, I will focus on the characteristics of LLMs that make them well-suited to help with career readiness preparation, from the grassroots stage (high schools, colleges), to later in your career, when you’re ready to land your dream role at your favorite company. We’ve already seen that Large language models (LLMs) are revolutionizing various fields, including interview coaching to find your first job, college admissions preparation, and preparing for job interviews while navigating various careers (experience a demo). Their unique properties enable personalized guidance based on individual performance, making them an invaluable tool in refining the human skills needed to be successful in any career. Let’s look at some of these properties in more detail and explore the science behind “why” LLMs are so well-suited to providing personalized guidance, and what constraints must be put in place to ensure a reliable output from these models. Advanced Natural Language Understanding LLMs possess advanced natural language understanding capabilities, allowing them to accurately interpret interview responses. They can comprehend nuances in language, identifying strengths and weaknesses in communication skills. The best reference for Large Language Models (LLMs) possessing advanced natural language understanding capabilities to accurately interpret interview responses and identify strengths and weaknesses in communication skills can be found in the paper "Improving Language Understanding by Generative Pre-Training" by Radford and Narasimhan. This paper introduces the popular decoder-style architecture used in LLMs, focusing on pretraining via next-word prediction, which enables these models to comprehend nuances in language and exhibit advanced natural language understanding capabilities. To take advantage of this capability, it is important to provide information and context to the A.I. model that are specific to your needs. There are several ways to perform this task, ranging from few-shot learning to fine-tuning, the scope of which is beyond the scope of this blog. Courses such as these from DeepLearning.ai can be extremely useful if you are new to this field. Adaptive Feedback Mechanisms These models utilize adaptive feedback mechanisms to tailor coaching based on individual needs. By analyzing interview responses, LLMs can provide targeted feedback, focusing on areas requiring improvement while reinforcing strengths. To better understand the science of LLMs and their adaptive feedback mechanisms to tailor coaching based on individual needs, you can refer to the following articles:
Attention Mechanisms & Transfer Learning LLMs leverage vast datasets to generate data-driven insights into interview performance. By comparing responses to successful interview patterns, they can offer actionable advice to enhance performance. One such dataset is the MIT Interview Dataset, which comprises 138 audio-visual recordings of mock interviews with internship-seeking students from the Massachusetts Institute of Technology (MIT). This dataset was used to predict hiring decisions and other interview-specific traits by extracting features related to non-verbal behavioral cues, linguistic skills, speaking rates, facial expressions, and head gestures. Modern day LLMs have some unique properties that allow them to exhibit similar capabilities with contextual information and new data, even if that data is not as comprehensive as the dataset described above. I briefly highlight two of these properties below:
Real-Time Computation One of the key strengths of LLMs is their ability to provide real-time analysis given structured data. This instantaneous feedback enables candidates to adjust their approach on the fly, improving their performance as they go. The architecture of LLMs, which are essentially complex neural networks, is optimized for efficient computation. These neural networks have already learnt a mapping between the input and output based on billions of parameters and are utilizing these learnt weights to perform mathematical computations at a rapid pace. This allows them to analyze conversational information such as interview responses in real-time, providing immediate feedback to users during these interactive sessions. Based on analysis and feedback, LLMs can help create personalized learning paths for career readiness preparation. They can even be tuned to recommend specific resources or exercises tailored to target areas for improvement, thereby maximizing their effectiveness. How can Generative AI help my organization with career readiness? In conclusion, the properties of large language models make them exceptionally well-suited for providing personalized career readiness preparation. Their advanced natural language understanding, adaptive learning mechanisms, data-driven insights and real-time computation capabilities offer invaluable support to individuals navigating the complexities of the pursuing their career goals. As LLMs continue to evolve, they hold the potential to revolutionize career development, empowering individuals to achieve their professional goals with confidence and competence. The reliability and consistency of the output from these LLMs is however heavily dependent on the quality of your input data and the precise definition of context that you can provide. At Relativ, we help organizations gather input data and create guidelines with sufficient fidelity for their A.I. models to infer “what good looks like”. We help them experiment with their own data and understand how an LLM works with different contextual information, so they can expand these capabilities and begin to measure various skills that individuals exhibit during their conversational exchanges. When tailored to specific job descriptions, these customized A.I. models can give end users a competitive advantage by not only identifying the skills they require, but also helping them improve their performance on those skills through personalized feedback. Head over to relativ.ai or reach out to us to learn how we can help you deploy your own AI models, infused with psychology, and linguistics, to empower your organization and end users with the career readiness skills they require to meet the challenges of the future of work. With the explosion of Generative Artificial Intelligence (GenAI), and the widespread adoption of Large Language Models (LLMs), there are widespread opportunities for organizations and individuals to augment their existing functions with AI. As with the introduction of any new technology, I have seen varied opinions from people ranging from being fascinated, to resisting change, and even attempting to disprove that the technology is actually beneficial, by trying every possible way to make the technology fail. Worse, we are constantly highlighting one-sided dangers of the technology, with prejudice and bias, without taking the time to understand why or how certain technologies can be beneficial, what its strengths are, and what its limitations may be. Public perception is often the biggest threat to innovation. Like many people, I have spent a lot of time experimenting with AI but haven't found a compelling explanation of "why" AI can help drive business outcomes. One of the key aspects that I've been focused on is the use of my own curated and contextual data, which has positively disrupted the outputs from these fantastic AI models. As I continue my learning journey through my career and through life, I’ve decided to create a short series of blogs about my findings and my experiments in the space of GenAI and LLMs. While it will primarily serve as a reminder of my own career pathway, I intend to make this information relevant and helpful to anyone taking the time to read it. Throughout my blog posts, I will include relevant resources to where a reader can find further information, should they wish to dive deeper into a certain topic. I hope you enjoy reading this series, as much as I enjoyed writing it. 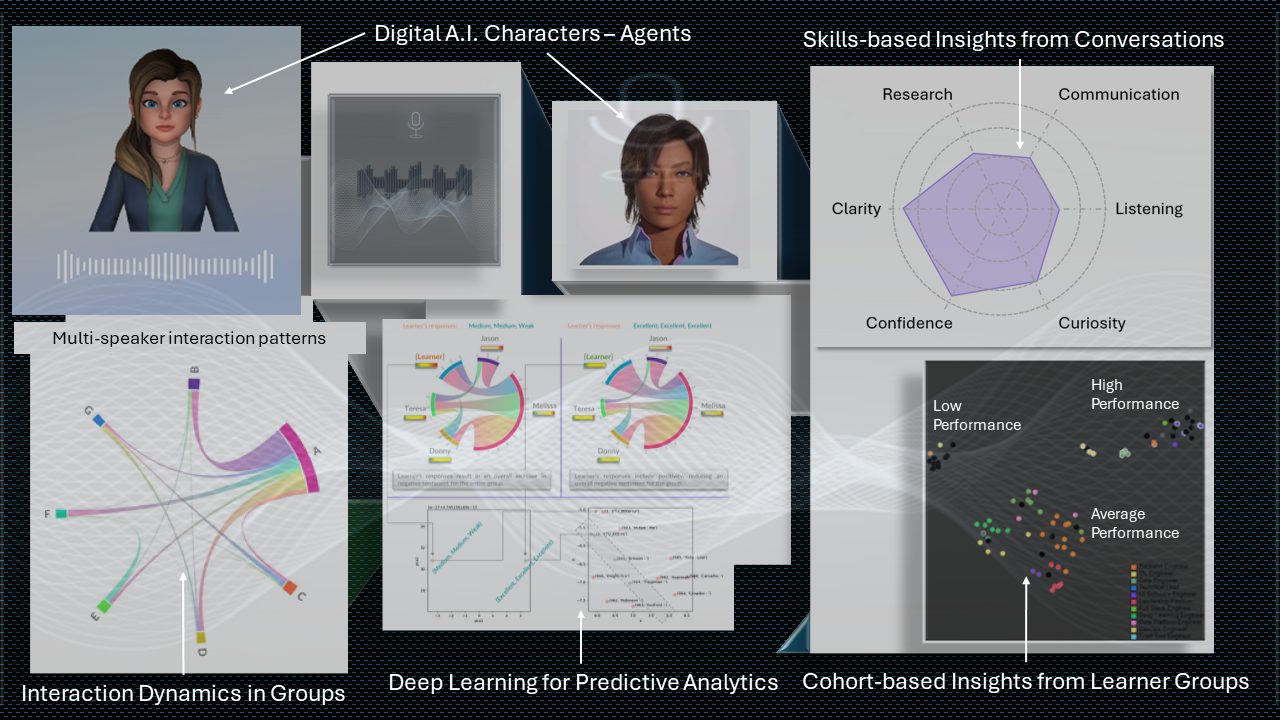 In my first blog post about this exciting area of research and application, I will aim to explain the inner workings of Large Language Models, and some of their characteristics, in a way that allows us to use a data-driven approach to decision making. The hope is that this information will allow the adoption of these AI models in our workplaces (and our personal lives), to augment our efforts, and help us be more productive, and efficient in the long run.
What are Large Language Models? Almost everyone that has heard of Artificial intelligence, has also probably heard of the term “Neural Network”. They are a specific architecture which allows computers to learn the relationship between input samples and output samples, by mimicking how neurons in the brain signal each other. The first Neural Network, called a Perceptron, developed in 1957, had one layer of neurons with weights and thresholds that could be adjusted in between the inputs and the outputs. A fantastic introduction to this topic can be found here. Large Language Models (LLMs) are a type of Neural Network. In contrast to the Perceptron from 1957, some of these LLMs are infinitely more complex, with nearly a hundred layers and 175 billion or more neurons. What do Large Language Models do? One of the first practical applications of neural networks was to recognize binary patterns. Given a series of streaming bits (1s and 0s) as input, the network was designed to predict the next bit in the sequence (output). Similarly, in very simple terms, Large Language Models can predict the next word given a sequence of words as input. If that is all that they can do, why are they so powerful and appear incredibly intelligent? The scope of this goes well beyond a blog post, but here is an incredible resource that will help you understand the inner workings of large language models. Characteristics of Large Language Models In the final sub section of this blog, I will attempt to highlight some properties or characteristics of Large Language Models. I will refer to these characteristics in various future blog posts, so the utility of these properties and their application areas can be better understood. It is these characteristics and properties that contribute to the ability of LLMs to appear to understand and generate human-like language.
What can Large Language Models help with? At Relativ, we have been experimenting with Deep Learning, Psychology, Linguistics, and Large Language Models, by qualitatively assessing the generated text across thousands of interactions, and continuously instruction-tuning these models to quantize their output. We have learned that when LLMs are combined with proprietary algorithms and curated data, their output can be transformative and insightful. When used in thoughtful conjunction around the end-user experience, as well as the intended business or academic outcome, we are starting to see some very promising results. We are already beta-testing these models in recruiting, sales, learning and development, retrospectives, and career readiness where early adopters are reaping the rewards of experimenting early, and gaining a competitive advantage from the learning that occurs. In the next series of blogs, I will attempt to describe how Relativ's models are being used in each of the above fields, and why they can be a game changer in the long run. I will refer to the characteristics of LLMs highlighted in this blog entry, for continuity and chain-of-thought (pun-intended), throughout this series. In the meantime, head over to relativ.ai or reach out to us to learn how we can help you deploy your own AI models, infused with psychology, and linguistics, to help you drive business outcomes. It's been a while since I had the time to update this blog. I was recently interviewed by Superbcrew, an online business and technology review magazine. I took the opportunity to elaborate on the effectiveness of Mursion and what the future holds in store for us. You can read the full interview by clicking on the image below. 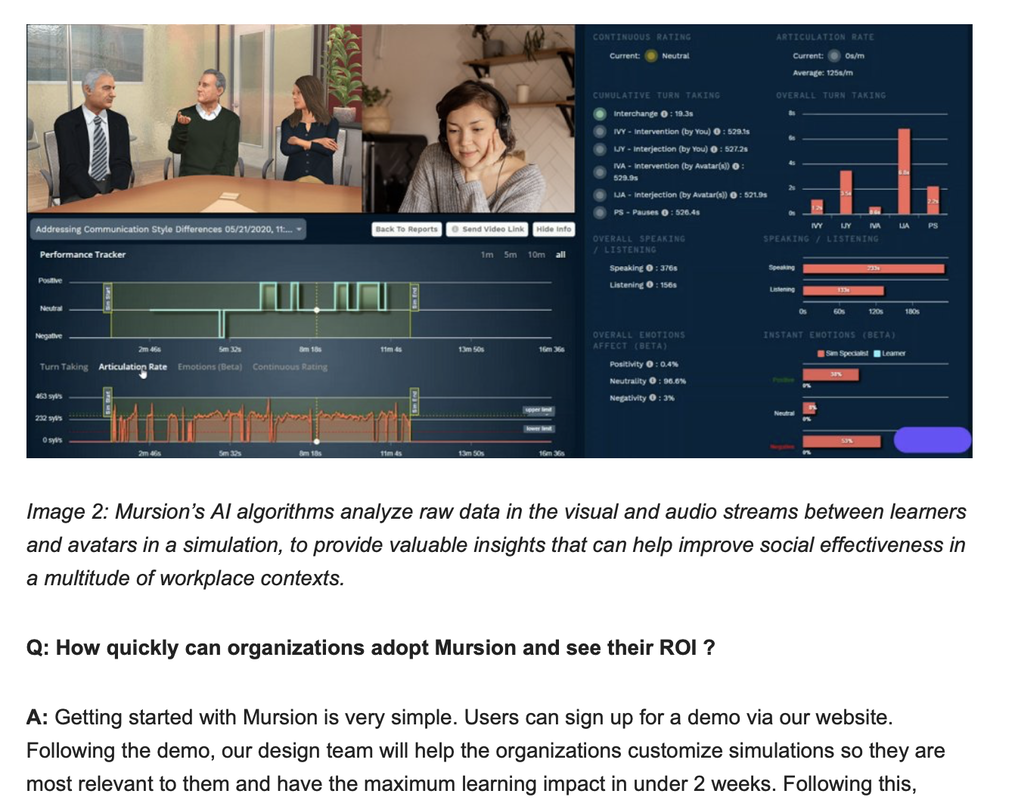 There are several techniques that are used for soft skills training in industries such as customer service, corporate leadership, healthcare and sales among others. The primary goal of any such training is to enable professionals to deal with difficult situations they may encounter in the real world. The theory behind training is that exposure to such circumstances will help enable quicker and better decision making. For several decades, live role playing has been seen as an effective methodology for soft skills training. There are several advantages that role-playing offers in contrast to other passive training methods. • It provides a safe space in which learners can make mistakes and try out new strategies of problem solving without being subject to the risks that are associated with such situations in the real world. • The active nature of the learning, requiring 2 or more-people to be involved automatically lends itself to new learning stimulus that includes cultural diversity, language, non-verbal reactions, personalities and other human characteristics that are not independent of the learning goals. For role play to be effective, there are certain pre-requisites that include actual physical locations, authentic real-world scenarios, and good actors / consultants all of which reinforce the concepts of situational plausibility and place illusion - two key constructs whose origins and importance I have described in a previous blog. In addition to these pre-requisites, the role playing scenario must be recorded so that participants can watch and reflect upon their performance. It is this combination of being in a realistic stressful situation and reflecting on the performance after the role-play that makes it effective - in other words, experiential learning occurs when role-play based learning is executed well. However, all the pre-requisites of role-playing make it logistically expensive and difficult to execute in a manner well-suited to learning. It is here that we can harness the power of virtual reality and avatars, to scale and amplify an existing training methodology. This is the essence of what we do at Mursion. In fact, several years of studying the VR alternative to role-play using avatars has led us to believe that this methodology is not only easier and cost-effective to scale while increasing outreach, but also maybe better and more effective than traditional role-playing techniques. Firstly, for learning to occur, it is important for one to experience a certain amount of discomfort. With traditional role-play, it may be difficult or awkward for an inexperienced role-player to push the learner outside of his/her comfort zone, without breaking the illusion that the situation is real. It takes this sort of pushing to trigger the mistakes that are so costly in real life. If a simulation is to inoculate the learner against the emotional reactions that trigger bad decisions, this pushing is essential. In VR, the mask of being behind an avatar enables the role-player to push the learner to take risks. The role-player is never visible to the learner – the learner never catches the role-player’s gaze; they never “connect” as humans. In fact, studies have shown that social influence is greater during interactions where a human is behind the avatars during these conversations. Thus, the role-player feels liberated to push the learner in ways they would find very hard to do repeatedly in a live context. Secondly, in the traditional sense, a role-player may not physically resemble the individual(s) who pose the real-life interpersonal challenges. The concept of standardized patients in healthcare are a prefect example, where it is very difficult to recreate a pediatric scenario of a 5-year old child with a medical condition for obvious reasons. With VR, avatars can be built to look and sound precisely like the people that you encounter at work, and with whom you may have negative interactions. This becomes critically important when issues of age, race and gender matter to the simulation. Additionally, environments can be customized so that it feels as though you are having the conversation in the same work environment where the conversation takes place. All of this allows us to meet the pre-requisites needed for effective role-play in a cost effective and logistically convenient manner.  Virtual reality technology and Artificial intelligence can help scale and create a very effective method of experiential learning. At Mursion, we focus on blending live human performance with AI-driven avatars to blur the learner's sense of what is real and what is not. Machine learning is used to gather role-player intent, digital signal processing (DSP) technologies are used to mask the role-player’s identity and advanced low-cost networking paradigms support bi-directional communication between multiple learners and multiple avatars within a single simulation session allowing us to scale training to the maximum. We are often asked the question of how this approach is scalable if a role-player is always needed in the system. The answer is multi-fold:
In the last 4 years at Mursion, we have seen evidence of learners trying their hardest to beat the simulation. In their effort to win, learners take conversational risks that they would never take in a live role-play. These strategies sometimes work, but more often than not, they fail. And it is this failure that prompts learners to reflect, learn and be better prepared. If you are trying to incorporate cutting-edge VR & AI simulations into the professional learning and development curriculum at your organization, come visit us at Mursion. And with that, I’d like to wish all of you a wonderful and prosperous 2019! In the last few years, Virtual Reality (VR) and Artificial Intelligence (AI) have been two topics of huge interest across various industries. Both these topics are so broad in terms of their application areas that it is almost difficult to find an industry that would not benefit from the use of one or both of these technologies. Application areas range from entertainment, to analysis, to training, assessment, and everything else in between. But what if we could combine the power of these two technologies, augment it with human reasoning, and create applications that lend themselves to entertainment, analysis, training and assessment among other things? We open a new door that now requires insight into understanding human psychology and how people behave when interacting with these technologies. More importantly, it becomes critical to design how these technologies manifest themselves when interacting with people. I’ll try to explain this concept within the boundaries of what we currently do at Mursion - a VR and AI based training platform designed to help acquire skills through experiential learning. Mursion was built on the foundational principle that difficult conversations in real-life can be simulated before they occur, to safely inoculate against unpredictable behavioral changes in the presence of stress. Many of us would agree that we have been at the receiving end of such events more than once in our lives - be it at work, at home, or in a new geographical location where socio-cultural practices differ from our individual perceptions of the norm. While experiencing Mursion, learners’ beliefs that the simulation is real and is happening in their physical space are continuously reinforced - this concept was well studied and published by Mel Slater (described further in one of my previous blogs). This is achieved by carefully stimulating the visual and auditory senses of the learner using Virtual Reality and Artificial Intelligence.  Virtual Reality is used to first create an authentic setting in which a learner can be positioned. Avatars (digital representations of humans) that are driven by a combination of Artificial Intelligence and Human Reasoning present the learning challenge. Multi-exemplar training, 360 degree feedback, and reflection are used as powerful learning mechanisms to help learners prepare to deal with difficult situations they may encounter on the job. To do this, we follow certain key principles that we have learned by analyzing data (no personally identifiable data is ever collected) or seeking feedback from hundreds of learners experiencing the platform:
(i) We design simulation scenarios as short vignettes, no longer than 7 - 10 minutes long. The content of the scenarios is both relevant and of high impact with respect to the learner. Virtual Reality allows us to position the learner in this situation by helping modify the visuals to match the context in which the vignette is occurring. For example, a conflict with a co-worker must occur in the workplace of the learner and not in a generic setting. We go to great lengths to customize the simulation content and model these using reference photographs that are relevant to the vignette being designed. (ii) We use a combination of Human Reasoning and Artificial Intelligence to create avatars (digital representations of humans) that blend seamlessly into the simulation setting. While the mechanics of this blending are proprietary, spoken dialogue on the Mursion platform is not driven by AI (I’ve highlighted the reasons in a previous blog). In fact, we have learnt from data that language, accents, and even vocabulary during these highly engaging simulations play a huge role in reinforcing the authenticity of the interaction. The more authentic the simulation, the better are the learning outcomes. (iii) All scenarios have discretely measurable objectives / goals for the learner. We leverage this to implement a 360 degree feedback mechanism and rely upon reflection as a powerful learning mechanism. Learners receive a video of their performance in simulation that can be shared with peers, coaches and others to seek feedback while also watching themselves and taking notes that night help them get better in subsequent sessions. We are now testing a system that uses Artificial Intelligence to analyze the audio and video streams of the learners to present the learners with highlights of their interaction - micro interactions in which they had a positive impact or a negative impact on their avatar counterpart during the simulation. While we are still studying and refining our approach to this analysis, there is sufficiently positive evidence that this data can be used to provide workforce analytics that may help re-organize teams for maximum productivity/efficiency and so on. (iv) We design simulations in a manner that does not reward rule-governed behavior. Once again, experience and data has shown that there are multiple ways to achieve a certain outcome during difficult human conversations. My good friends, advisors, and mentors William Follette and Scott Compton have been at the forefront of helping us study the science behind this concept. As they would put it - “We can only tell you certain things you should not do during a conversation (e.g. do not dig your nose!) - everything else that you try in order to have a positive impact on your counterpart is fair game”. What is more, every conversation and every person is different - it is critical that you assess your own impact on others and change your behavior (verbal and non-verbal) accordingly until you achieve the desired outcome. (v) And finally, we rely on the concept of multi-exemplar training - learners are exposed to several simulations around particularly difficult situations, but each simulation may have a different learning outcome. No two simulations are ever the same (unless it is required for an assessment). Learners see a variety of demographics in the form of avatars, with each one posing a unique learning challenge. The more simulations a learner performs, the more prepared they can be to handle stressful conversations that may occur in the real-world. While there may be several other ways that AI & VR can be be combined depending on the context of the application, we, at Mursion, have encountered the need to study human psychology when using these powerful technologies. We have also learned that blending human reasoning with VR and AI can help create a technology that can be used in a plethora of ways. I will try to address some of these in a future blog. But without the science that helps us understand behavioral psychology when interacting with technologies, it is difficult to truly harness the impact they can provide. If you would like to learn more and see if such technologies may be relevant or impactful, please drop us a note and come see us at Mursion. We’re in the bay area and always happy to entertain visitors! Those of us creating engaging and effective solutions in the Learning and Development (L&D) space, have invariably heard the acronyms VR (Virtual Reality), AR (Augmented Reality), MR (Mixed Reality) and most recently, XR. While the first three acronyms have specific meaning in a traditional sense, the ‘X’ in XR is interpreted differently by experts in the field. One such interpretation is “Cross Reality” spanning the use of Virtual, Augmented or Mixed reality - Wikipedia has a detailed description on the history and origins of this term. So which one of these “pseudo” realities is the most effective for learning and development? The answer to this is dependent on several factors, the foremost of which lies in the question itself - determining what “effective” means in the context of the specific learning and development. For a methodology to be effective, it must first be engaging. In other words, a learner must feel the desire to be accepting of the proposed methodology as a learning tool. Next, the methodology should create a retention of knowledge. And finally, the methodology must instill confidence in a learner to apply the knowledge in real-world circumstances. With these three goals in mind, we can explore the use of VR/AR/MR or XR (a combination of realities) in achieving the desired learning and development goals. In my first blog, I highlighted some basic design principles that must be followed while creating VR experiences - principles that rely on the effective replacement of the senses in order to create engaging applications. AR and MR differ in the fact that the former is used to overlay / augment the real world with additional information and the latter performs a similar function, with the additional burden of anchoring the information to a physical object in the real world. There are plenty of mechanisms (and applications) in which any of these realities can be achieved using a combination of multiple sensors and visual displays that are beyond the scope of this blog. What is of importance is determining whether the application in question benefits the learner in achieving the three goals established above. To illustrate, it may be best to visualize what these different technologies look like in the context of learning and development - soft skills are one such area of critical importance (highlighted in a previous blog), independent of the industry in which an individual may be employed.  Computer generated props can be displayed (rendered) on a computer screen, in a VR device (headsets such as the Oculus Rift or HTC Vive), or through an AR display (devices such as the Hololens). In the first image on the left, everything that is displayed is virtual - the classroom, the trees, the books and the avatars. This simulation is great in order to give the sense that a learner is in a classroom and is most effective when rendered via a VR device. Depending on the level of immersion desired (different levels of immersion create varying degrees of engagement in different learners), one may choose to simply use a large television screen or computer screen to experience this simulation. The second image shows a “hologram” of the girl avatar rendered via an AR display (in this case, the Hololens). The chair in this image is real while the girl avatar is computer generated. More importantly, the girl is anchored to the chair. The “anchoring” construct involves complexities not described here, but for simplicity of understanding, we may consider this “Mixed Reality”. If well-implemented, a swiveling chair would result in the girl avatar spinning as if really seated on it. One can imagine the use of this modality to create a virtual learning companion in the natural learning environment (e.g. in homes of students). The third image shows the girl anchored to the chair, but also an orange-red circle. This circle is a cursor that allows one to interact in the “Mixed Reality” environment. However, the cursor is not anchored to any object in the real world - it is simply an overlay (via the display) on the real world. This may be considered a prop in “Augmented Reality” and could change its color, or description as it hovers over different objects in the “Mixed Reality” setting. Such informational overlays could be used to assist a learner in achieving their goals and gradually phased out to increase the learning challenge. As you can see, the terms AR, VR and MR are all unique, yet intertwined.
At Mursion, we focus on using simulations to foster empathy and induce positive change in human behavior. While we await the adoption of these XR technologies at scale, we keep our platform compatible with existing delivery modalities - television screens, laptops and mobile platforms - while continually striving to create the most effective and engaging content for the delivery medium. We prefer to think of XR as “Experiential Reality” - a simulated reality that facilitates learning via experience, independent of the medium in which the simulations are delivered. If you’re wondering how best to incorporate simulations into learning and development, get in touch with us or better yet, schedule a visit to beautiful San Francisco and come see us at Mursion! Alexa, Siri, and Google Assistant are household names today. Advances in Artificial Intelligence (AI), more specifically machine learning and natural language processing, have empowered us to use voice to interact with machines. This adds a new dimension to existing literal and gestural interfaces and potentially overcomes the complexity of user interface design when navigating complex / deep menus. The simplest example is that of using Alexa to play a song - a user interface on iTunes or similar would require that you type the name of the song in the search field, apply any filters to narrow the search, and finally selectively push play based on the results. Instead, these actions are replaced by your voice, eliminating the need for a sequence of user inputs thereby speeding up the interaction. But perhaps the most important aspect of voice-based interactions is that it has eliminated the need for proximity with the machine and / or it’s physical user interface. From a psychological perspective, it plays into human nature - we primarily communicate with other humans through voice, body language, and gestures. Why can’t we do the same with machines ? Note that the word “communicate” is very different from the word “interact” - and it is here that we begin to encounter barriers with all aspects of AI related to Natural Language Processing (NLP). To help better understand the difference between interaction and communication, let’s use the following example. Try asking your favorite voice assistant to order a coffee: "Siri, can you place an order for a cappuccino using the Starbucks app? " The results will likely be locations of the Starbucks stores that are in your vicinity. More specifically, the result would have been appropriate if your question was "Find the nearest Starbucks " In order for you to achieve your intended goal (ordering a cappuccino), you must continue issuing voice commands or interacting with your phone until the above task is complete, but the whole process feels transactional in nature. They are short, simple constructs, with each subsequent instruction having a definitive outcome. But what if you had this same exchange with a friend or co-worker? You will likely begin with a discussion of what the outcome should be, exchange complex constructs during your interaction and never worry about the order in which the exchange of information occurred. In addition, you will have no problem dealing with variations in accent, language, grammar, or even if the task was completely inter-twined with another. It is obvious from this very simple example that you can interact with Siri or other voice assistants but can never really communicate with them (at least not today). So what causes this barrier and can it be overcome? Communication is a very complex construct. When we communicate as humans, we perform several conscious and subconscious tasks such as reading the other person’s facials, gestures, body languages and tone of voice in the context of the interaction so we can best reciprocate to achieve a desired outcome. Machines have no such knowledge and in particular, are devoid of contextual information. Several researchers are investigating the possibility of giving machines the ability to perform some of these tasks, but the challenge lies in the nature of the machine to acquire this ability. Over the years, this has been termed as “Artificial Intelligence” and encompasses several sciences of which machine learning has gained popularity since it provides machines with the capability to generalize taught constructs. There are however two things to bare in mind: • The word “Artificial” refers to the fact that machines can be made to “appear” intelligent and are not truly intelligent. • Machines needs a lot of clean data in order to “learn”.  Illustration: It is easy for us humans to deduce all the hierarchical relationships above even if only two (Manager, Peer) are given. Illustration: It is easy for us humans to deduce all the hierarchical relationships above even if only two (Manager, Peer) are given. To illustrate, if a relationship A <> B and a relationship B <> C are taught, humans are capable of deducing the relationship A <> C. Not only that, humans are also capable of deducing the reverse relationships B <> A, C <> B and C <> A (see example to the left). In fact, it is this ability of ours to learn via extrapolation / deduction that makes us the dominant species on the planet. For a machine to learn all these relationships, humans must provide data that includes both positive and negative examples of all of these relationships. In other words, humans must provide a machine with sufficient data for it to learn to “compute” all these relationships. And this is the AI effect - if a machine can compute a relationship, it is not truly intelligent. The advantage of machine learning is best seen when a problem is complex and non-linear and hidden relationships between the input and output need to be discovered. And this is where the biggest barrier in teaching a machine how to communicate exists. The subsets of inputs and outputs are infinite.
Take for example, the common situation where employees engage in a 5-minute conversation with a manager about a workplace dispute. My previous blog post addresses why soft skills are so critical to increasing productivity and efficiency in the workplace and how training can help better handle such situations. The workplace dispute could be around any topic involving budgets, processes, methodology or even personal in nature. One can only imagine the number of unique ways in which this conversation may play out in real life depending on a number of factors including but not limited to personality types, context surrounding the conversation, history and relationship between the people, etc., re-iterating that infinite space of inputs and outputs during communication. Let us for the sake of argument, assume that AI can be programmed to hold an extremely engaging conversation within constrained boundaries for 5 minutes. This readily lends itself to a training application where learners can practice their soft skills. Even in this case, the machine will need sufficient data from real conversations in these areas to communicate effectively with a learner. More importantly, the machine will require contextual information and read the learner’s body language, tone of voice, and other non-verbals to effectively engage them in the training. How is it possible to provide the machine with this learning data unless we have a database of such conversations readily available to us ? Every time there is a new pathway of conversation (data that the machine has not seen and hence cannot deduce a relationship), a human will need to provide the machine with both positive and negative examples to incorporate this pathway into its repertoire. In other words, there is always a human in the loop. The question we ask ourselves is this - where do we want to place the human in the loop ? At Mursion, we combine the computational power of AI with that of human reasoning to create seamless, engaging and customizable simulations that allow learners to practice soft skills. By placing the human at the end of the chain, we avoid having to teach the machine the complex art of communication - instead, we focus on harnessing the power of artificial intelligence to drive digital representations of the human (avatars) thereby reducing the cognitive load of the humans that inhabit the avatars. The end result is a simulation platform where subject matter can be rapidly customized without the need for re-programming. When combined in this manner, virtual environments and avatars reinstate the constructs of situational plausibility and place illusion (Slater, 2009), leading to the suspension of disbelief in learners. This creates a very realistic, effective, and safe training environment. To learn more about how this training can be applied to organizations and how results translate to real-world performance, come visit us at Mursion - and as an added benefit, you can walk to the Golden Gate bridge after your visit! |
AboutArjun is an entrepreneur, technologist, and researcher, working at the intersection of machine learning, robotics, human psychology, and learning sciences. His passion lies in combining technological advancements in remote-operation, virtual reality, and control system theory to create high-impact products and applications. Archives
April 2025
Categories
All
|
 RSS Feed
RSS Feed